
In this blog post, I reflect on the things that stood out to me while shipping multiple ML products over the last year.
These reflections represent solely my personal views and experiences, not those of my employer. Examples referenced are either drawn from publicly shared company materials or are purely hypothetical.
In 2025, AI transformed product development workflows in remarkable ways.
This past year, I kept myself busy improving and scaling our existing ML model pipelines. I demonstrated value in a 0 → 1 ML use-case that is now core part of the eco-system, going beyond the 0 →1 pit into a stable state. I explored replacing existing ML systems with cheaper and better systems, including LLMs and simpler linear probes balancing speed and scalability.
Some things, like the time to create V0s or MVPs of an ML product, drastically went down. In some other cases, LLMs completely replaced traditional ML models. However, the core principles of ML lifecycle became even more prominent; The most successful ML systems we deployed were characterized by an evaluation-centric design philosophy.
Broadly, in this post, I categorize these musings along the traditional dimensions of data, evaluation, cost surface, engineering systems, and feedback loops. These together are summarized as the following principles:
- ML product velocity is built on “boring” infrastructure, not brute speed.
- The data is never going to be 100% “clean” or “gold”. Accept the noise or, better yet, create silver data.
- Optimize the cost surface, not just the accuracy of the model.
- Do not shirk away from ensembles.
- Feedback loops are invaluable; their absence is your product’s nail-in-the-coffin.
- Coding agents are indispensable luck potions, but use them well.
My TL;DR summary is:
Nothing has changed, and yet, everything has changed. It’s not in the what, but rather the how.
Shipping ML fast is built on “boring” infrastructure
While speed is a given, the true accelerators, though, are in the pre-existence of a stable architectures across data pipelines and warehouses, evaluation frameworks, training pipelines, and feedback systems. For instance, building non-standard frameworks for evaluation per use-case can cause not only maintenance overheads, but also create significant hazards for brittle evaluation. Creating evaluation datasets (real or synthetic) follows similar standardization challenges; if using real data, they also necessitate investing in data warehousing and analytics even before building a V0.
I view V0s [Version Zero] not as a fully fledged product, but rather as an opportunity for rapid learning and correction. Even existing ML systems can have V0s to replace components. As we develop these systems, we want to be able to quantify the gap between the model’s behaviour and the reality of the production environment, i.e., where are we wrong, and how wrong are we?
We must start with the end state in mind and work backwards to what a V0 must look like. The clarity of what a north star looks like helps set milestones for both short-term and medium-term goals. Even if the full north star vision is never fully realized, a forward-looking design that anticipates future requirements has the advantage that the system is inherently extensible. This avoids costly architectural overhauls in the future.
This isn’t always possible with fast timelines in mind, in which case the outline of a vision at least helps recognize deviations and whether those trade-offs are acceptable buy-ins at the moment. Tradeoffs can be design compromises, a smaller subspace of the product where the ML will be applied to, or a subpar model that can be trained iteratively and intentionally. The foundational corners that cannot be cut remain the data, evaluation, and feedback loops. These are non-negotiables and must either be implemented robustly from the start or rigorously scheduled as immediate follow-up tasks after the initial iteration.
Start from the evaluation, not the model
Most problems have varying costs for different types of errors. Knowing what mode of failures is expensive is invaluable for optimization. If false negatives cannot be tolerated (for example, cancer detection), then we must prioritize it as the critical metric during iteration. The ideal scenario is to achieve the best of both sides: perfect recall and zero false positive noise. A V0 is most likely to be a single model that will face precision-recall tradeoffs. If we can solve for high recall first, we can tune the false positive rates incrementally. Subsequent model pipelines can even employ multi-stage models to target these individual metrics.
Alternatively, noise levels can be minimized with humans in the loop who review the false positives. This reduces the urgency of tackling this type of error
An illustrative use-case discussed publicly this year involved adverse event detection in healthcare conversations. Early approaches such as keyword search proved insufficient for rare events, leading to high-recall modeling with human-in-the-loop review to manage false positives.
at the expense of reliance on domain experts who possess deep, nuanced knowledge of the problem space. These domain experts not only filter out obvious false positives but also provide valuable feedback on the edge cases that allow us to incrementally support them. These false positive labels also provide harder negatives for future evaluations.
Pure synthetic data cannot strive to do this without significant investment. I would love for us to get here but this is an investment that is unlikely to be at scale and generalized as a platform without investment this year.
They make your V0 move beyond the vacuum of statistical metrics to a trustworthy, deployable product.
On the other hand, we still need evaluation toolkits and frameworks to iterate on V0. In an ideal world, these pre-exist. These evaluation frameworks connect an evaluation dataset to the model performance on the failure modes and the critical metrics we want to measure. While it isn’t possible to maintain a single framework across every ML use-case,
A generalized Evals platform is also possible as a separate investment, and something I am excited to see succeed in 2026.
the rise of coding agents allows taking existing robust frameworks and adapting to new use-cases quickly. The existing principles of experiment tracking, per data point telemetry, and analysis remain vital to iterations to a viable V0 and beyond.
This also shifts the evaluation from purely model metrics to a real world failure modes. For a model that detects dialogue breakdown on chats or phone calls, we want to know what specific kind of breakdowns the model handles well and what are those cases it entirely misses. Answering these requires understanding the operational constraints of prototype ML systems as well; if the model is purely text-based, we won’t be able to assess voice-based emotional cues that could signify breakdown. Deploying a V0 in such a constrained subspace requires rigorous analytics to be able to disambiguate such cases and measure the production performance.
The Mirage of Gold Data
The success of all ML products depends inherently on data to train and evaluate the ML systems. We have all crossed the waters of “clean” datasets like MNIST that are near-perfect with minimal label noise. We can strive to create similar conditions in real production settings. But these attempts should not predate initial iterations to a V0. Post V0, we can focus on data cleaning tasks. Until then, we strive towards a “good enough” dataset state over a “gold” standard.
Hard negatives define real systems
Consider the hypothetical task of detecting refusal to transfer in chat conversations; this is a specific type of conversational breakdown. Suppose this issue occurs rarely, in less than 1% of the chat volume. Regardless of employing a standard ML model, a fine-tuned LLM, or an LLM API, the model’s ability to perform accurately in this imbalanced setting is entirely dependent on the quality and representativeness of the evaluation (and training) data.
Given the rarity of the positive class, data gathering must be explicitly targeted. We could leverage humans and their explicit feedback or labels on conversations. A well-established data warehouse that logs every turn of a conversation is also an invaluable asset. This infrastructure enables fast analytics, allowing engineers to filter calls or conversations using specific phrases, keywords, or semantic matching heuristics. While not yielding perfect gold data, a simple SQL query can quickly surface the most straightforward examples, providing an almost “magical” starting point for data collection. We could use targeted annotation workflows where humans, LLMs, or AI-assisted humans meticulously review chat logs to identify potential positive samples. These are gold standard as well, once human preferences are calibrated for the task by measuring inter-annotator agreements.
Along with collecting positive examples, we need negative samples - the conversations where the refusal to transfer issue is absent. We could just use clean chats with no breakdown issues whatsoever. While these make it easy for the model’s metrics to look excellent, they deviate from true production performance.
To build a robust system, the problem space must be made harder intentionally. Hard negatives are not just the simple absence of the target issue (X); they must include samples of related but distinct breakdown issues, such as frustration, a system outage, or general confusion. These are cases that are visually or semantically close to X but are fundamentally different. The contrastiveness that boosts model performance does not simply come from discriminating between X and not X. It arises from the ability to differentiate between X, not X, and not Y. The model must learn to distinguish the specific target (refusal to transfer) from all other forms of conversational complexity or breakdown.
This framing is analogous to contrastive learning setups, where the decision boundary is defined not just by positive and negative classes, but by semantically adjacent or confusing alternatives.
To gather these hard negative samples, we could apply the same annotation or analytical setups used for positive examples. We could use sparse explicit feedback about specific issues like frustration to assume it did not contain the issue we want to model. In that mode of operation, if these conversations have both issues, we assume that the human labeler or end-user felt frustration was more important than refusal. So this collection process can feel somewhat “janky,” though necessary.
In addition, we could gather these examples through creative heuristics and partial human review. We could even ask LLMs to modify clean calls (i.e no issues) to inject issues. Despite not being pristine gold labels, they are often exactly what is needed to dramatically boost a model’s performance and make the system truly “work like magic.”
The case of subtle noise
With these setups, we can chase the mirage of gold labels. In practice, it is either unnecessary to have a ton of gold labels, or impossible to obtain a high volume of pristine labels in a low-calorie manner. However, note that the presence of significant noise in the dataset will naturally prohibit any meaningful learning. These issues are easily observed though. The harder and more insidious problem is subtle noise.
For example, in annotation tasks that require human judgment and interpretation, a degree of inherent noise is inevitable. Even with rigorous guidelines, differences persist between annotators.
We could measure the inter-annotater agreement (IAA) and recalibrate until we are satisfied; recalibration would involve changing the rubrics, updating standard guidelines, and extensive training. The reality, though, is that the data will still have discrepancies that are borderline human interpretation differences.
Consider the preceding example where a single turn in a chat exhibits both ‘frustration’ and ‘refusal to transfer.’ In such a scenario, two different labelers are likely to categorize that instance very differently unless this scenario is codified explicitly in the annotation guidelines.
Now we have a choice - do we keep this data? This may depend on several factors. A thorough qualitative analysis of the label distribution and the nature of disagreements can tell us a lot. This can be manual annotation analysis. This ties to understanding where and why the current model fails, particularly if it struggles with specific, ambiguous examples. We must also consider this along with the other dimension of whether the model introduces new, unexpected failures that humans don’t make.
Tainted data can be gold
Now, consider a model trained to extract data from chat conversations. We would like to mimic human reviewers who either approve or reject these extractions. In this context, we are modeling a human’s judgment, which is inherently noisy. We hope for the law of averages to normalize and even out these individual human errors.
This assumes annotation noise is approximately unbiased and independent. Systematic bias or correlated errors violate this assumption and require explicit intervention (see above footnote).
But if there are guideline gaps or annotation calibration gaps, these errors are no longer errors. They become features that the models need to learn to mimic, even if they are not explicitly codified. The data is “tainted” if one were to look at the objective truth of what the extracted value should be. But we aim to do at least as well as humans, in which case, perhaps counter-intuitively, this tainted data is the gold truth.
Given that these errors can compound, we could build a robust feedback mechanism for detection, diagnosis, and correction. If we are able to dissect these error modes, we can run ablation tests, temporarily removing this data from the training set. Annotators can be retrained simultaneously so that fresh data is aligned with updated guidelines and can be integrated into the dataset. We could make the model flag high-uncertainty examples or detect these low-confidence regimes, in which case these examples receive special attention in a review queue. We could build LLM analyzers that scan and rate human annotations, too. Lastly, if it’s not a critical issue, we could simply live with it.
Across projects, I’ve never seen truly “perfect” gold data. What matters is not purity, but knowing the imperfections around where the data lies and where it breaks.
Optimize the Cost Surface, Not Solely Accuracy
The optimization metrics very rarely remain the model metrics like precision and recall. This is especially true with the proliferation of LLM APIs, where the evals should be further grounded on a wider cost surface encompassing model vendors, thinking budget, modalities (text, audio, image), as well as the usage patterns, latency requirements, error modes, and total cost.
Spinning up experiments across these dimensions, even on a smaller scale, is useful to understand failure modes. You get a ton of data on what dimensions work great on specific error modes at this point in time. For example, thinking budget may help solve an edge case that requires alignment of the conversation sequence, while it may perform worse on a different kind of reasoning task. It is possible that future LLM versions that are more capable solve this by default, so knowing the coverage of error modes at any given point in time is highly useful.
The per-unit cost budget (for e.g., per call or per chat) often dictates what subset of these vendor models is available for a usecase. This cost analysis remains a prerequisite to understanding the compatibility of the ML system for scale.
However, the prices of LLM APIs have decreased significantly and very quickly, albeit at the expense of the reliability of the service. The pay-as-you-go model is very cheap, but not as reliable on latencies or service uptime as provisioned throughput.
Lastly, the cost surface must also take into account how the ML product fits into the existing ecosystem, optimizing a further set of tradeoffs. These can include focusing on the cost of a specific type of error (false negatives vs false positives, tuned thresholds for balancing these errors). More generally, it includes the human costs associated with the ML predictions; High false positive rates that involve significant human review time for the above refusal-to-transfer issue can mean suboptimal use of human experts.
Human costs include review time, cognitive load, escalation overhead, and trust calibration.
There is also the somewhat qualitative assessment of iteration time across the ML system evolution timeline, and the factors influenced by the ecosystem’s evolution itself.
As systems mature from V0 → V100, scale often changes. Even stable systems need to anticipate increase in volume. ML Infrastructure scaling needs would need to be considered.
A model that achieves 99% accuracy but has a prohibitive per-call cost and long latency can be projected onto a far worse point on the cost surface than a model with 95% accuracy that is fast, cheap, and requires comparable or smaller engineering effort and minimal human intervention. Connecting this back to V0s, the concept of “shipping fast” requires rapidly finding a local optimum on the cost surface that is better than the current state, acknowledging that the initial model is merely a starting point for continuous, cost-aware iteration.
In essence, the iterations that matter are the ones that move the system to a better point on the cost surface, not the ones that optimize a single metric in isolation. They are effectively aligned with progress towards the north star.
ML Lifecycle iteration
Iteration speed in ML comes from de-risking change, not aiming to replace systems instantaneously. This is essentially a software engineering principle.
Iteration without breaking production
We want to answer the question “Can this model or ML system safely influence the world yet?” Shadow mode, A/B testing, and canaries are are levers that allow us to answer this question under different deployment constraints (regardless of replacement models or V0s). Shadow mode
We can deploy replacement models (ML System ‘B’) or even the V0 in a shadow mode deployment. A portion, or ideally all, of the live production traffic is simultaneously routed to both the existing and replacement systems. The outputs from both systems are logged and stored for analysis, even if the outputs from the shadow model don’t influence the primary workflows.
is ideal when outputs can be observed without consequence; A/B testing
Shadow mode isn’t applicable in systems that involve a feedback loop, such as multi-turn conversational agents, which often require the model’s output to genuinely influence the subsequent user actions to gather meaningful data. In such cases, A/B testing can determine the impact of the new system by routing a portion of the traffic to these systems that actively influence the environment.
is necessary when outcomes depend on interaction like multi-turn conversations. Canaries
With canary deployments, we could divert a small portion of production traffic to these newer versions and monitor system and business metrics. This effectively is a phased rollout where we are able to quickly detect model drifts, data skews, or regressions in the ML system (assuming a representative sample in this subset). With automated health metrics, we can rollback to a known healthy deploy if critical issues exist.
allow us to incrementally expose real users while retaining rollback guarantees. Note that we could build e2e simulation systems that can accelerate these measurement workflows even before the system hit real-time production environments.
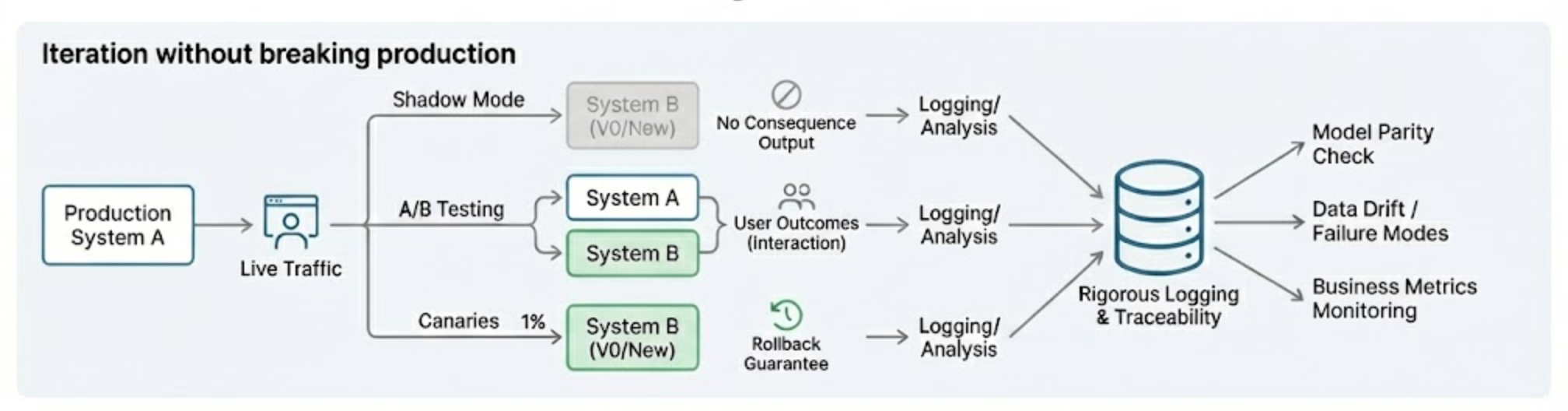
All of these levers are backed by rigorous and potentially excessive logging for future analysis. First, it allows fast verification of model parity. Second, the traceability provides affordance for exploration of data drifts and failure modes as we shall see in feedback loops section. The underlying notion remains that monitoring business metrics in production environments is still vital, and we need to repeat this process with every iteration of the ML system.
The Ensemble Approach
So far, this has been an all-or-nothing approach because we need to decide: system A or system B? We don’t need to decide right away; Ensemble approaches give a nice middle ground. One system effectively outperforms the other within a specific, well-defined subset of the problem space, an “optimization surface,” where system B outperforms system A.
Our goal here is to replace system A entirely (aka become legacy). If this System B can cover a majority of the volume (e.g., 70%), iteration speed should not prevent us from deploying this subset model at this point. It is still a win, at the expense of maintaining two systems. We must prioritize getting system B into parity, while also iterating on mistakes made by system B. It’s the best of both worlds, until we move entirely to the world of System B.
The core principle lies in identifying a subspace where System B provides a clear advantage, whether that is superior performance, higher accuracy, or lower operational cost, compared to System A. With V0s, this is often clear because of the design choices we have had to make head-on. Once this subspace is identified, the system must be able to employ cheap heuristics (e.g. simple, fast, and reliable eligibility checks) to determine if an incoming request falls within the realm of System B. Within this eligible subspace, traffic is routed to System B. Outside of it, System A maintains its role.
An advantageous surface here is being able to rely on confidence thresholds for system B. If the model’s output falls below this threshold, the system can automatically fall back to the existing System A. System A becomes a definitive safety net in maintaining the overall quality and reliability of the service, while allowing gradual performance gains in System B.
The primary cost of this strategy is the need to maintain two production systems (A and B) simultaneously for a period of time. This dual maintenance burden can be a necessary trade-off for risk mitigation and faster iteration. In fact, V0s rarely replace existing systems entirely; they earn their way into production by expanding the subspace they can safely handle. Established feedback cycles and evaluation infrastructure can in turn accelerate the expansion of system B’s subspace to that of system A.
Feedback loops are vital for V0 → V100
A production system without a feedback loop is effectively running blind, destined for irrelevance. System health metrics provide operational feedback around latency, throughput, and error-rates. Explicit or implicit user feedback can map to business metrics through clicks, interactions, and acceptance of model predictions. We want to be able to continuously validate that the ML product is delivering value and to use that operational and user data to rapidly drive the next iteration cycle.
Telemetry of the request as it flows through the ML system provides not only observability but also real-time analytical visibility. Be it usage tokens of the LLM or the confidence scores of a model, these provide direct feedback around system health. Logging even those reasoning summary tokens is useful to further categorize and analyze distributions of these reasoning texts, which in turn allow us to detect anomalies. For example, it’s possible that there is an error in sending chat logs to the LLM API, and the majority of LLM responses bring up the lack of the chats as an issue. Observability here allows categorizing on the reasoning texts to identify such patterns.
While automated metrics are vital, human review remains the gold standard for high-quality ground truth and identifying novel failure modes. Previously, human review was mostly post-hoc. Models deployed in production will encounter edge cases and concept drift. Humans explicitly provide feedback directly as they encounter these or through annotation tasks. With LLM-driven simulations or modeling, we upfront these human evaluations during iterations. These can be accompanied by LLM analyzers as well, but a human in the loop to review the failure modes remains essential.
Therefore, the successful transition from V0 to V100 is not a single leap but a continuous cycle powered by these deployment, logging, monitoring, feedback, and analysis best practices, aligned with the north star vision. Each time, data dictates how to improve the system next.
AI-assisted ML Engineering in 2026
In fast-paced timelines, a comprehensive “platform-first” approach isn’t always feasible and is mostly suboptimal for the earlier iterations of the ML system. However, a conscious effort to reduce the technical debt inherited with clean, well-structured, optimized code can reap long-term benefits in unintentional ways.
For example, in a scenario where the new feature’s productionization piece shares 70% commonality with established patterns, the path forward becomes significantly less burdensome. Even if the immediate goal requires a small amount of duplicate code for a V0 or initial release, the critical advantage is that the team is not starting from scratch. This is because we know the existing system has been battle-tested.
The momentum generated by having a clean, familiar foundation is everything. It drastically reduces cognitive load, accelerates development, minimizes the surface area for new bugs, and ensures that the team can iterate rapidly. The later efforts to refactor, generalize, or integrate the feature into a broader platform become much more straightforward and less costly. These active prioritizations directly influence the agility of the team.
On the aspect of agility, the current generation of LLM powering tools like Codex or Cursor, are powerful force multipliers. The capacity of these assistants to rapidly generate initial versions of code, content, and even entire systems has dramatically reduced the cost and time required to build a V0. The culture has quickly moved to “experiment-first” without the lengthy pre-launch development cycles.
However, the true value of these assistants is unlocked by teams with established discipline and expertise. If the team already possesses a robust framework for measuring performance, tracking metrics, and conducting rigorous A/B testing, LLMs can dramatically accelerate their development cycles. This allows ML Engineers to focus on the planning: higher-level architectural and strategic problems around data gathering, model construction and evaluation. Without existing infrastructures or clarity around these processes, these agents can obscure fundamental errors. Knowing what to measure and how to interpret the results remains the paramount skill. The AI assistants act as a highly productive junior partner, but the engineers must still serve as the senior architect and as a quality control layer.
In the past year, the aspect of synthetic data has come up constantly as a way to unlock new ML use-cases. Historically, creating annotations for entirely new tasks has been cost-prohibitive and time consuming. LLMs are transforming this remarkably.
With zero or few-shot examples, we can use LLM annotators with great accuracy, bootstrapping human labelers. We are now able to generate realistic synthetic training examples with mutli-dimensional constraints (persona, tone, emotion, speech errors, noise etc.) really well, expanding the diversity of these silver datasets.
This also unlocks simulation frameworks without needing to curate a clean gold dataset. These advancements also unlock adversarial simulation that offer unprecedented testing of the system even before we have deployed it.
Given these new quests in the ML lifecycle, evaluation frameworks aren’t just about the core ML system. Even your LLM judge needs human calibration to some extent (even if it’s just the engineer creating it). Everything is now about evaluation discipline. Evaluation must continue to rigorously assess complex attributes like coherence, safety, and faithfulness, moving beyond model metrics.
None of the principles we talked about above have changed; the problem space has changed. Even prompt optimization with techniques like DSPy is converging to familiar patterns; we effectively get a hybrid data-driven modeling approach to tuning prompts. It’s still not a free lunch, and that’s the point.
Conclusion
There is a low cost and speed barrier to V0s with LLMs, coding assistants, and the ease of creating synthetic data. However, my experience so far has been that these advances amplify the underlying hidden technical debt in ML systems.
Fast iteration does not come from better models alone. It comes from knowing what to measure, having data that reflects real-world ambiguity, understanding the cost surface you are optimizing over, and building feedback loops that teach the system what matters in production. Importantly, these are not new ideas, but they are easier to ignore when progress feels rapid and instantaneous with AI assistants.
The teams that ship ML reliably design systems that can be observed and corrected without breaking production. They treat V0s as instruments for learning, not endpoints. They accept imperfect data early, invest in evaluation discipline, and let systems evolve their way into production.
AI-assisted development changes how quickly we encounter these decisions, not whether we have to make them. In that sense, the art of shipping ML remains the same: reducing uncertainty faster than the problem shifts, without losing visibility into why a system behaves the way it does.
I asked ChatGPT
A meta note is how useful AI assistants have been in reviewing early drafts of my blog posts. This feels like a writer-editor collaboration where the writer still has the agency of these edits. In full transparency, this post was written entirely by hand, fed to ChatGPT as a first draft for section by section critique, and edited by me based on suggestions made (mostly good, and some utterly non-sensical). Gemini was used to generate images from the finalized contents of the sections along with a draft drawing outlined on Excalidraw. My speed has increased, but these are still my words.
to summarize this post in one line, and it was aptly the following:
Speed is a consequence. Measurement is the work.
]]>
 Alt title: Engineering Agency in the Age of Agents
Alt title: Engineering Agency in the Age of Agents









 Makes you look at the gif very differently, doesn’t it?
Makes you look at the gif very differently, doesn’t it?